Les limites de ce tableau comparatif des langages que tout le monde a vu
Avez-vous déjà vu ce tableau ?
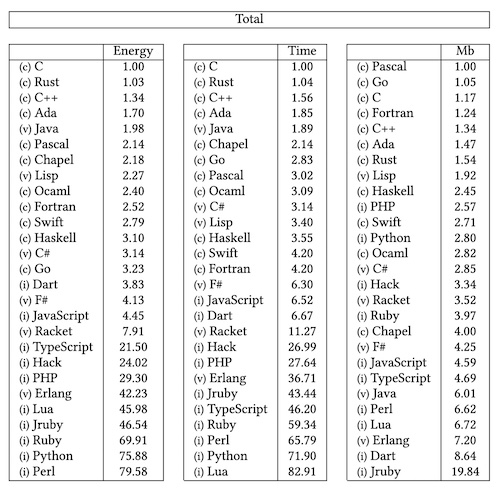
Personnellement je le vois partagé à plein d’endroits, dans plein de contextes : sur LinkedIn, dans des présentations, des formations, etc. Le plus souvent avec peu d’explications et de recul sur ce qui est représenté.
Il s’agit d’une comparaison de l’énergie, du temps et de la mémoire dépensés par différents langages de programmation pour réaliser des tâches similaires. Il est issu d’un papier de 2017 (en) écrit par 6 chercheurs portugais. En première lecture, en lisant seulement le tableau, on a envie de justifier le choix de son langage préféré par sa présence dans le top d’une ou plusieurs colonnes et/ou de se lamenter sur la trop grande utilisation de langages moins performants.
De quoi s’agit-il exactement ?
Les auteurs du papier ont mesuré les performances des langages en utilisant des implémentations de 10 problèmes de programmation utilisant les mêmes algorithmes écrits dans le cadre du Computer Langage Benchmark Game (en). Ils ont utilisé le RAPL (Running Average Power Limit) pour mesurer l’énergie utilisée et ont fait 10 essais pour chaque algorithme. Leur démarche semble raisonnable. Ils prennent, dans le contenu du papier, les précautions nécessaires pour expliquer la difficulté de comparer les langages.
Les benchmarks sont toujours limités.
Comme on peut le lire sur la page Wikipédia, les développeurs du CLBG le disent eux même (l’emphase est de moi) « the JavaScript benchmarks are fleetingly small, and behave in ways that are significantly different than the real applications. We have documented numerous differences in behavior, and we conclude from these measured differences that results based on the benchmarks may mislead JavaScript engine implementers ». Ici la citation parle de javascript mais on pourrait certainement la généraliser à d’autres langages.
Il faut toujours prendre les benchmarks, quels qu’ils soient, avec précaution. Il y a potentiellement de nombreux aspects à analyser : latence, nombre de requêtes par seconde, différents types de ressources utilisées (cpu, ram, bande passante, …), différents types de machines, différents types d’applications, … Dans le papier on voit que selon ce qu’on regarde, énergie, temps d’exécution ou mémoire, les scores sont très différents. Selon le contexte, on peut accepter de dépenser plus de mémoire pour aller plus vite, et inversement.
De plus les environnements d’exécution ne sont pas facilement comparables. Par exemple, la machine virtuelle Java standard se comporte mieux si le programme est exécuté pendant une longue durée : on a alors de la compilation à la volée (Just In Time), adaptée à l’architecture de la machine hôte, ce qui améliore le temps d’exécution et le nombre d’opérations (requêtes par exemple) par seconde.
Toujours dans l’exemple de Java, chaque mise à jour de la JVM apporte des améliorations de performance. Il y a aussi de nombreuses options que l’on peut passer pour modifier son comportement, en particulier celui du Garbage Collector, ce qui peut énormément changer les performances. Et il existe depuis quelques années la possibilité de compiler et d’exécuter du code natif avec GraalVM, pour une empreinte mémoire et un temps de chargement très réduits mais en perdant la compilation à la volée. Ces nuances ne sont pas dans le tableau.
Je ne connais pas les autres langages et leurs univers aussi bien que celui de Java, mais je suppose qu’on pourrait apporter les mêmes objections.
Il ne s’agit pas d’une véritable application
Le benchmark n’analyse pas une véritable application. Le résultat n’est donc pas forcément comparable aux performances attendues dans la vraie vie. Les algorithmes très demandeurs utilisés dans ce test ne sont pas ce qui sera demandé dans le cadre d’un projet typique en entreprise ou autre contexte. Un serveur d’application Web qui utilise une base de données, applique quelques règles métier et génère du json ou du html est-il comparable aux applications analysées ici comme « Allocate, traverse and deallocate many binary trees » ou « Match DNA 8mers and substitute magic patterns » ?
On ne choisit pas un langage uniquement pour ses performances au runtime
De plus, les langages de programmation n’existent pas en eux même de façon isolée, mais font partie de tout un écosystème, d’une stack. Et les stacks sont choisies pour leur intérêt dans un contexte particulier.
Il y a des spécialisations.
Python par exemple est très utilisé pour les applications de machine learning, de data science, surtout quand les algorithmes sont encore en cours d’élaboration : l’intérêt est de tester rapidement des idées avec des POC, pas d’avoir les meilleures performances du marché. Et avec cette spécialisations, les langages en question peuvent avoir au sein de leur niche des performances relativement plus intéressantes que ce que montre le benchmark.
L’écosystème autour du langage est aussi un facteur déterminant : la richesse de l’univers Java, avec une quantité impressionnante de librairies et frameworks très documentés et très utilisés, est un facteur déterminant dans le choix de cette stack technique. Sans parler de la possibilité de trouver des développeurs compétents qui maîtrisent cet écosystème. Il est beaucoup plus facile de trouver des personnes expertes en Java ou Javascript qu’expertes en C.
Peut-on analyser la consommation d’un processus en isolation ?
Un appareil numérique a une consommation d’énergie de base, même s’il ne fait rien. De plus l’augmentation de sa consommation d’énergie avec la charge n’est pas toujours linéairement corrélée à celle-ci (en). Enfin, il y a d’autres processus qui font varier sa charge.
D’accord, nos solutions sont peu efficientes
Nous sommes d’accord que l’accent est mis depuis très longtemps beaucoup plus sur l’expérience développeur que sur l’efficience des solutions. Je suis assez perplexe de voir que l’on écrit quasi systématiquement deux applications aujourd’hui pour la plupart des projets : une API et une application front complexe avec un framework de SPA, là où il y a 10 ans on aurait généré toutes les pages côté serveur pour un résultat comparable.
Si on va plus loin, l’exemple de la mère de toutes les démos (en / youtube), où en voit en 1968, des personnes travailler en réseau, avec des emails, de l’hypertexte et des documents partagés est assez intéressant : on a de la marge avant d’être limités dans nos usages par la puissance de nos machines. Autres exemples : il est possible de faire tourner mastodon sur un Apple II (en), et un processeur vieux de 20 ans suffit à Perseverance pour explorer Mars.
Je voulais ajouter quelque part les nuances nécessaires autour de ce tableau comparatif que je vois souvent. Le choix d’un univers technique n’est pas qu’une question de langage et de performances. Et il n’est pas raisonnable d’imaginer un passage (par exemple) de Java à C dans les entreprises : ce sont des univers peu comparables, en termes d’outils, de documentations, d’usages possibles et de talents disponibles.
Optimisons déjà dans notre univers
Il y a déjà beaucoup à faire sur l’optimisation des solutions existantes sur les technologies répandues, sans parler de tout ce qui est possible en termes de conception fonctionnelle.